I’ve developed a new package for R known as rdatastore that is avaliable at cloudyr/rdatastore. rdatastore provides an interface for Google Cloud’s datastore service. Google Cloud Datastore is a NoSQL database, which makes provides a mechanism for storing and retrieving heterogeneous data. Although Google Datastore is not useful for storing large datasets, it has a number of useful applications within R. For example:
- Saving and loading credentials for use with other services.
- Caching data. This is implemented using datastore in my version of the memoise package.
- Saving/loading universally used pieces of data (e.g. parameters, options, settings) across systems or between work/home.
- Storage and retrieval of small (<10,000 row) datasets. Useful for integration of summary datasets.
The last two reasons are the primary motivation for developing rdatastore. Parallelized pipelines can simultaneously submit results to datastore (across many nodes or machines), and the results are obtainable for analysis within R. Settings can be updated on one machine and retrieved on others as well, obviating the need to modify virtual machines or scripts in many cases.
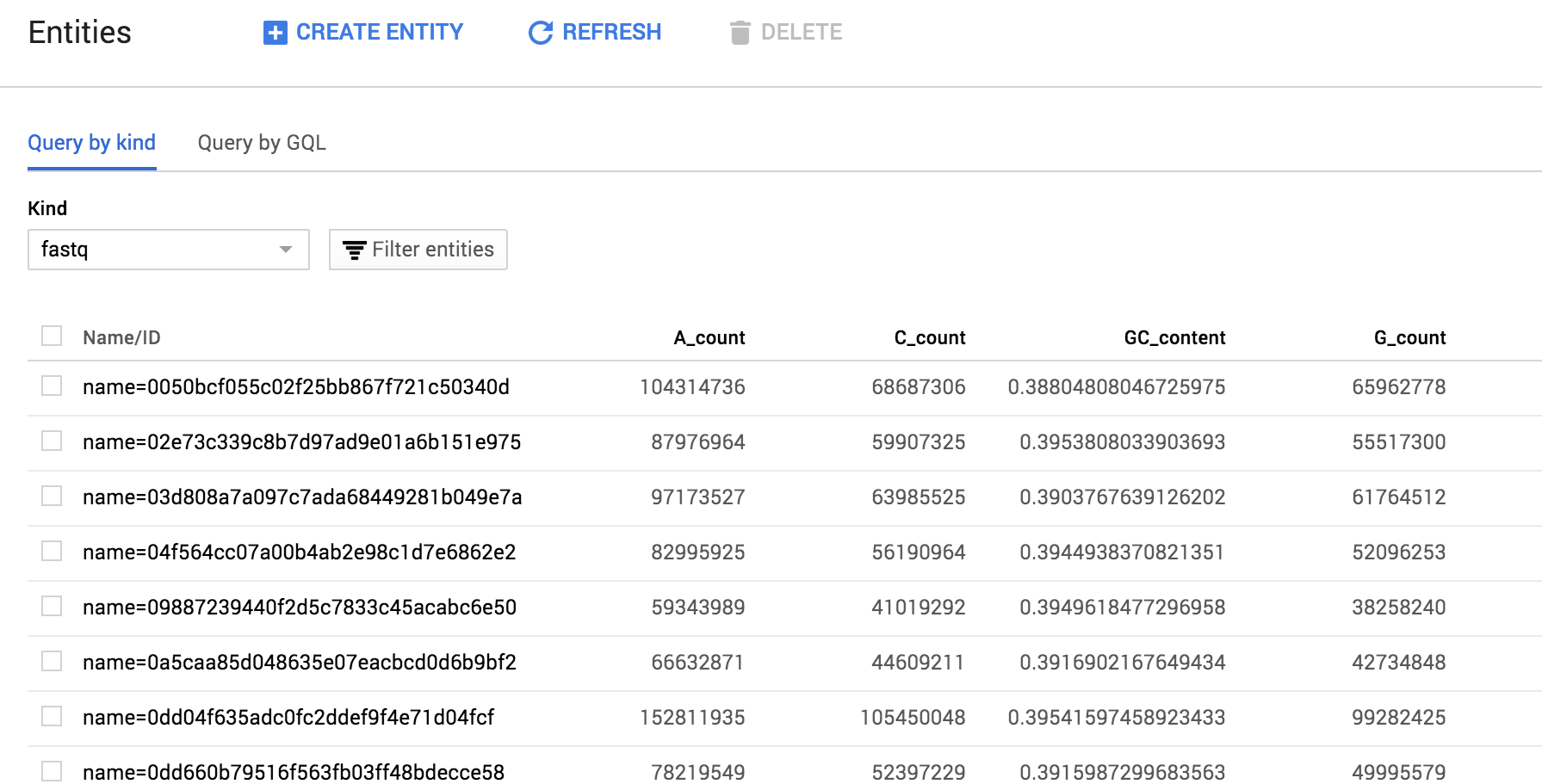 __The datastore interface can be used to view and edit data.__
__The datastore interface can be used to view and edit data.__
Setup
- Setup a Google Cloud Platform and create a new project.
- Download the Google Cloud SDK. This provides a command line based
gcloudcommand. - Install rdatastore
devtools::install_github("cloudyr/rdatastore")
Usage
Authentication
library(rdatastore)
authenticate_datastore("andersen-lab") # Enter your project ID here. rdatastore will authenticate using Oauth.
Storing Data
commit()
Individual entitites can be stored using commit(). You have to supply a kind (which is analogous to a table in relational database systems). You may optionally submit a name. Any additional arguments supplied are added as properties. Datatypes are inferred from R datatypes. For example:
commit(kind = "Car", name = "Tesla", wheels = 4) # Stores a new entity named 'Tesla'
Result
| kind | name | wheels |
|---|---|---|
| car | Tesla | 4 |
Important! Stick with basic datatypes like character vectors, integers, doubles, binary, and datetime objects. Not all datatypes are supported.
I designed rdatastore to make it easier to append data rather than overwrite it. This is abit against the grain as far as other datastore libraries go. For example:
commit(kind = "Car", name = "Tesla", electric = TRUE) # Stores a new entity named 'Tesla'
The entity will now be:
| kind | name | wheels | electric |
|---|---|---|---|
| Car | Tesla | 4 | TRUE |
If you want to overwrite the entity, you can use keep_existing = FALSE, and the original data will be wiped and replaced.
When using commit() you can omit the name parameter in which case Google datastore will autogenerate an ID for the entity. I’m not sure where this is useful. You won’t be able to look the item up without knowing its ID or by performing a query on the entities data.
lookup()
Retrieve data by specifying its kind and name.
lookup("Car", "Tesla")
| kind | name | wheels | electric |
|---|---|---|---|
| Car | Tesla | 4 | TRUE |
gql()
You can query items using the Google Query Language (GQL). GQL is a lot like SQL.
# Lets commit a few more items
commit("Car", "VW", electric = FALSE)
commit("Car", "Honda", make = "Odyssey", wheels = 4)
commit("Car", "Reliant", make = "Robin", wheels = 3)
gql("SELECT * FROM Car")
| kind | name | make | wheels | electric |
|---|---|---|---|---|
| Car | Honda | Odyssey | 4 | NA |
| Car | Reliant | Robin | 3 | NA |
| Car | Tesla | NA | 4 | TRUE |
| Car | VW | NA | NA | FALSE |
Notice that some some properties are NA because they were never specified.
We can also query specific properties - but this will only return entitites with those properties defined.
gql("SELECT make FROM Car")
| kind | name | make |
|---|---|---|
| Car | Honda | Odyssey |
| Car | Reliant | Robin |
You can also filter on properties with GQL:
gql("SELECT * FROM Car WHERE wheels = 3")
| kind | name | make | wheels |
|---|---|---|---|
| Car | Reliant | Robin | 3 |